

Unpacking the Digitization Issue
Digitization is a tricky issue—it has been both a blessing and a curse for cultural institutions.
On the one hand, although institutional missions prioritize access, most of a cultural institution’s collection remains in storage and inaccessible to the public. Usually, institutions just don’t have the space to display everything in their vast collections, no matter how many times they might expand. For example, Wikipedia estimates the Art Institute of Chicago’s collection size to be around 300,000 works (though, honestly, I feel like that number should be much bigger). When I was a student at the Art Institute, we were told that the museum displayed less a third of its collection. That number has probably increased significantly with the Modern Wing expansion in 2009, but the Art Institute can hardly display everything. Moreover, not all works in a collection are suitable for display. Some works may be at risk of deterioration. Others may contain sensitive content. Digitization, therefore, not only ensures access is granted to a greater extent, but it also, importantly, helps with preservation. Now, instead of bringing out a fragile, decrepit book from climate-controlled storage, the Art Institute can provide an individual with access to its digital images. Even better, the museum can put the images online for international audiences to view.
On the other hand, digitization is costly and burdensome and it produces and entirely new asset for an institution to maintain. How an institution defines “access” can impact that cost. How institutions decide to provide digital access can vary greatly.
Take this work from the Art Institute of Chicago:
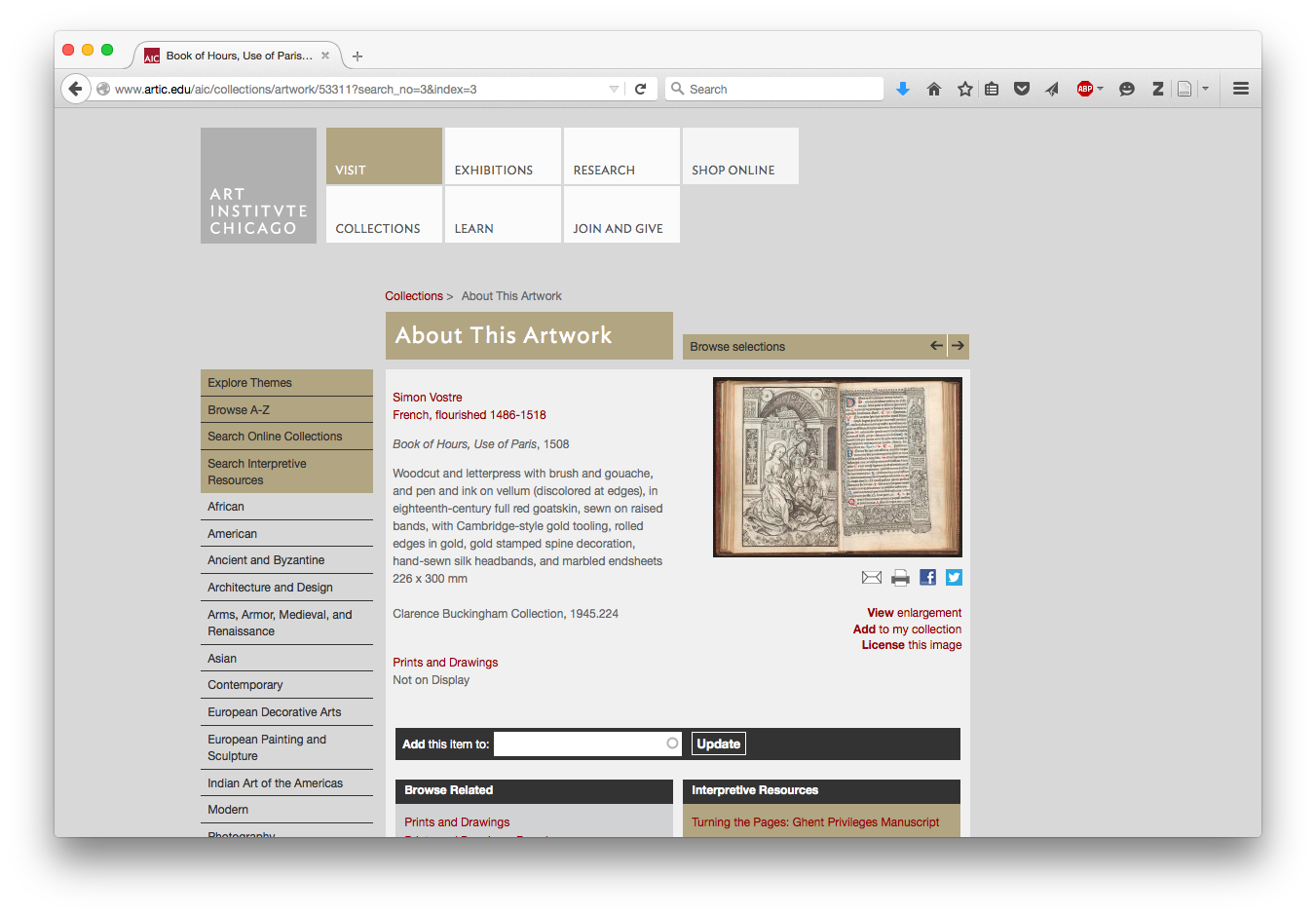
http://www.artic.edu/aic/collections/artwork/53311?search_no=3&index=3
The Art Institute has digitized a two-page spread from this Book of Hours, a work not on display. A short description of the book is included, but it’s not clear how many pages are in the book or if more digitized pages are available.
Compare this with an example from the British Library, which makes available 8 of the 52 pages of a Ballet Festival pamphlet, bound with seven other works. The British Library’s online record includes additional notes as to the names of the dancers and performers and the stage’s design.
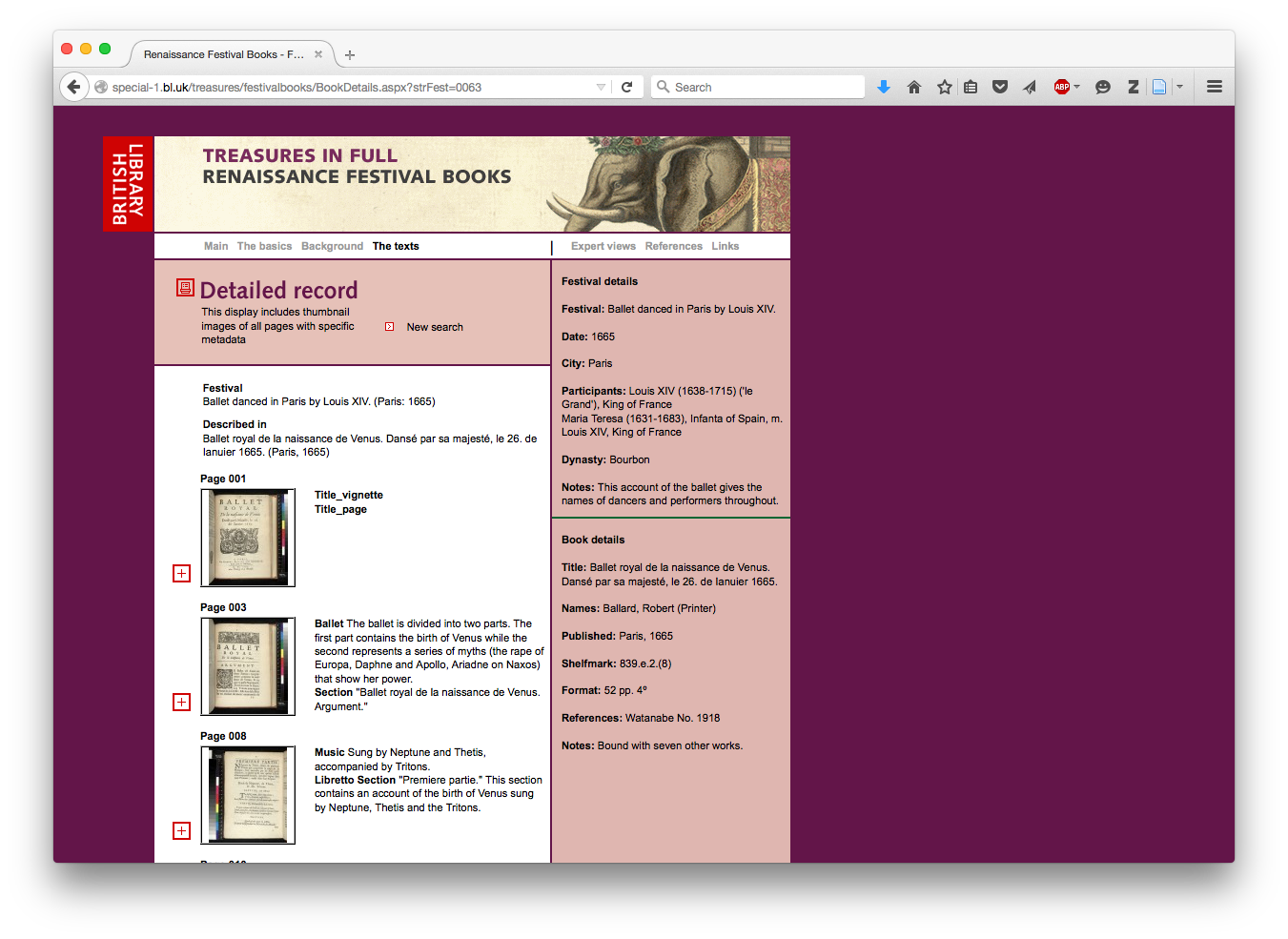
http://special-1.bl.uk/treasures/festivalbooks/BookDetails.aspx?strFest=0063
Is access more successful in one case than the other? Or is access satisfied in either case? If not, access may have been restricted for completely logical reasons. Not only is digitization time consuming, but it can also get pretty complicated when it comes to the law. Let’s take this step-by-step.
Step one: copyright clearance
Putting the two previous examples aside, not all works in collections are in the public domain. First, a cultural institution must check the work for any copyright restrictions. For works still in copyright, institutions must balance the legal obligations to honor the authors’ intellectual property rights against their own responsibility to make collections available. Such obligations can make digitization astonishingly expensive. This is true whether an institution is seeking an author’s permission to digitize a work, is conducting a copyright search to locate the author, or is attempting to determine whether an orphan work is still in copyright or falls in the public domain (I like to call this copyright purgatory). How long and hard cultural institutions are willing to search can greatly impact costs.
This obligation is not exclusive to cultural institutions: you, too, would be required to perform this due diligence for your own personal use. It is no wonder that institutions often begin by digitizing their works in the public domain.
And what if you digitize an orphan work in copyright and place it online? Well, then you might expose your institution to a lawsuit. To comply with copyright and better manage risk, cultural institutions are (understandably) selective about what they put online.
Step two: digitizing the work
After you clear a work’s copyright (or not), you can make a digital reproduction. Naturally, this requires more money. Yay! How much money? One 2010 report estimated it would cost a staggering €100 billion to digitize the collections of Europe’s museums, archives, and libraries. How this breaks down per institution is unclear. Some collections are more expensive to digitize than others: digitizing an illuminated manuscript with hundreds of pages requires much more care and effort that digitizing one two-dimensional painting. Institutions can turn to technology to reduce costs, but not everyone has the same resources at hand.
Step three: maintaining the digital collection
Now the work is digitized, right? Great! Even more decisions, obligations, and costs arise. For example, cultural institutions must decide things like: what resolution, size, and format to make a work available online; how to manage and store a digital file and its metadata; how to best maintain a digital collection; what level of access to grant when viewing digital images on-site and online (yes, they can be two different things); and how to provide digital files to the public in the least burdensome way for ease of administration. Consequently, establishing and managing an online cultural institution can become just as time-consuming as managing its physical version.
Step four: keeping it all going (after finally getting it started)
It gets worse. Before you can digitize anything, you have to figure out how to pay for it. In the past decade, cultural institutions’ obligations to digitize collections have increased while government funding has consistently decreased (sad face emoji). During this same decade, new solely-online organizations have created competition for cultural institutions. These organizations operate at a fraction of the cost compared to what is required to manage a physical cultural institution and its online presence. It’s become imperative that cultural institutions compete in order to stay relevant.
So, where does all the digitization funding come from? I mean, it seems ironic that cultural institutions are strapped for cash when they have some of the most valuable objects in the world in their possession. But they can’t exactly sell stuff off for money. Instead, charging for digital reproductions has become a business model that monetizes the value of those collections and generates revenue for further digitization and ongoing maintenance.
Digitization, Online Collections, and Surrogate Copyright
Once a work is digitized and becomes a commercial asset, how do you maintain ownership and control over it after it is uploaded to the Internet? How do you ensure reference to your institution is preserved, as well as the name of the original author? How about the title of the piece? The period of creation? The culture?
You do most of this by claiming a copyright over the digital reproduction as a completely new original work (or rather, through that pesky surrogate copyright). A copyright enables a cultural institution to license the image to others to use, while establishing the specific terms for how they must reference the artist and the institution.
As I’ve mentioned before, this can get a little sticky. Many works—like pottery or coins—were never intended for copyright protections. These objects provided a utility for the people who made them. They were also created well before copyright ever existed. And, if made today, such objects would (generally) not receive copyright protections under copyright law.
By contrast, other works—like our two book examples—would receive copyright protections today. However, these works also were created before copyright ever existed, which means the original author(s) never enjoyed the IP protections that we recognize today. Not only was the original book never under copyright, but also the book’s author(s) never invoked the right to make a digital reproduction to place and sell online (for obvious reasons). The point is that claiming a copyright to these digital reproductions is a completely brand new copyright and restriction over an item that was never restricted in the past.
In the two examples, both the Art Institute of Chicago and the British Library claim copyright over the images. The British Library does so very clearly through a copyright notification under each image:

http://special-1.bl.uk/treasures/festivalbooks/pageview.aspx?strFest=0063&strPage=001
The Art Institute of Chicago also claims copyright, but much less clearly. First, a copyright notice isn’t posted near the image, but there is a link to “License this image” underneath the photo:
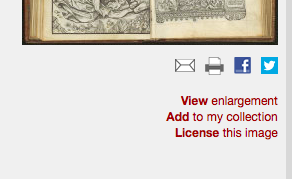
http://www.artic.edu/aic/collections/artwork/53311?search_no=3&index=3
Click on “License this image” and you’re taken to a page where you can request a price:
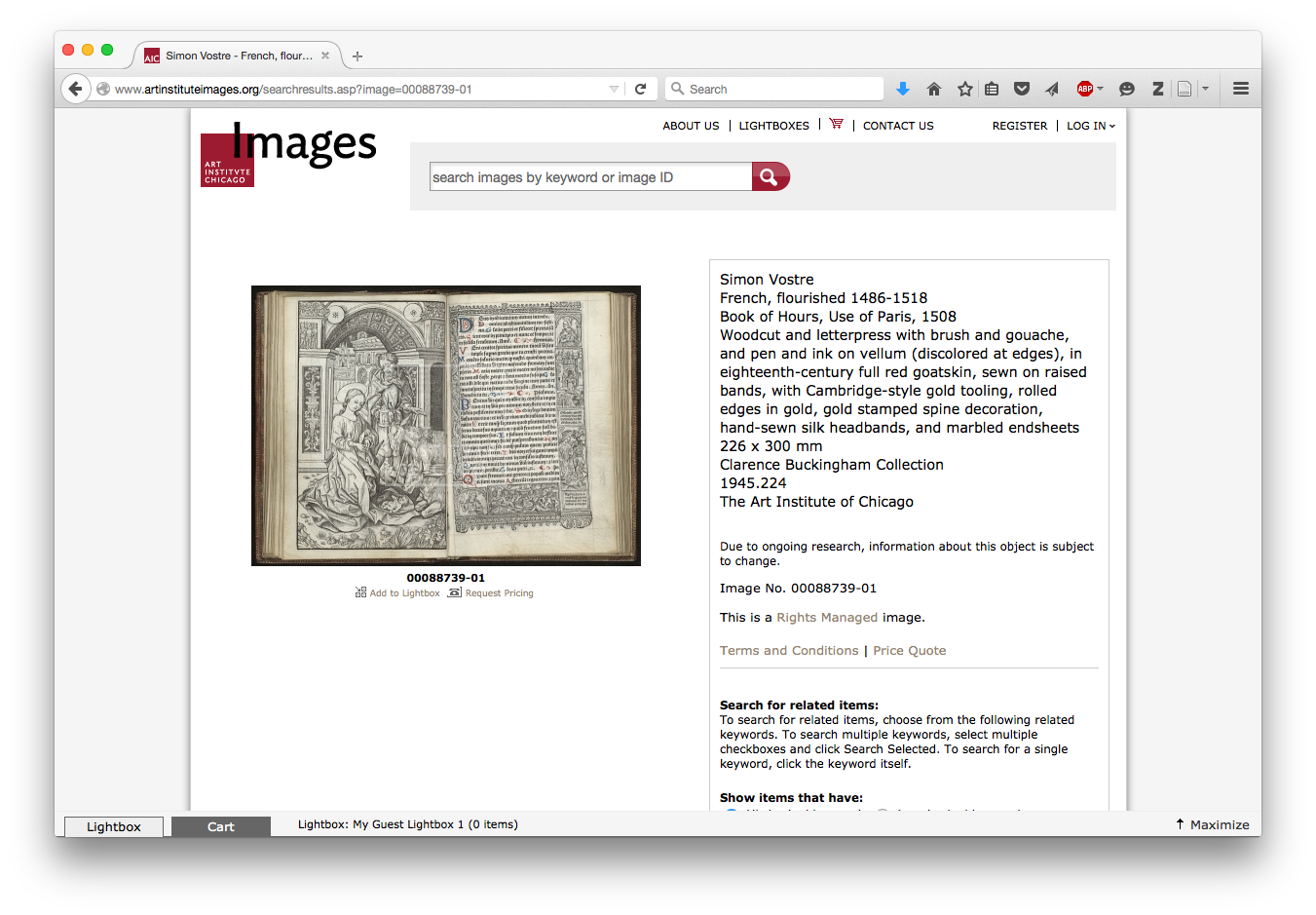
http://www.artinstituteimages.org/searchresults.asp?image=00088739-01
Both of these things make it clear there’s some sort of restriction over using the image. However, any specific details for what is allowed are still unknown. Luckily, I figured it out: I went back to the original page for the Book of Hours and had to scroll all the way down to the bottom of the page to find the word “copyright.”
http://www.artic.edu/aic/collections/artwork/53311?search_no=3&index=3
See that tiny “Copyright” at the bottom? I clicked on it and was redirected here:
http://www.artic.edu/copyright
Okay, great. This is basically for the content of the website, but I’m looking for the rules on image stuff. Next, I clicked on “Terms and Conditions” and finally found the relevant information:
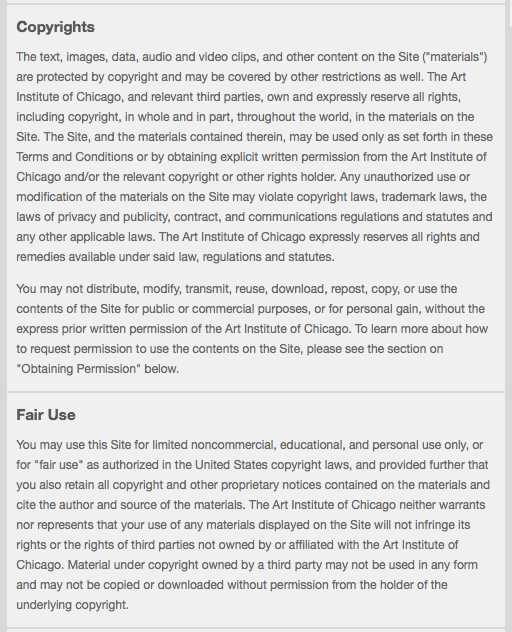
http://www.artic.edu/node/1727
Okay, so it’s not intuitive, easy to find, or very clear how users are supposed to respect the rights claimed by the Art Institute of Chicago. That’s some pretty broad and strong language, too. I’m discouraged by how complex the language is and how exactly it applies to the website. So, if it’s hard for me (a lawyer) to work out what I can and can’t do, it’s definitely hard for a member of the general public to do the same.
Trying to Rationalize Surrogate IP Rights
Not all cultural institutions that claim copyright over their images are looking to get paid. Several institutions claim copyright over the image and make various resolutions available online for free—so long as you don’t use the work in a commercial manner (once it becomes commercial payment is usually required).
In reality, most institutions don’t make much money from selling digital images of their collections. Some even operate their digitization schemes at a loss. Of course, any decrease in revenue generated by the sale of those images would be missed. Money is money. However, the commercial benefits that accompany copyright are often just an added bonus to the real goal: cultural institutions restrict use because they want to maintain the greater educational context of an object’s digital image once it is made available via the Internet. The context that surrounds a work—the culture in which it was originally made, where it was discovered, how it was used, who made it, and so on—is important to preserve. Preserving this context for an online audience is made even harder by the ease at which digital images can be downloaded and quickly disseminated.
In conclusion, cultural institutions have been faced with a new dimension of stewardship: digital stewardship. Cultural institutions aren’t trying to cash in on their collections; they’re designing policies for digital collections that support education and access pursuant to their missions. And, ultimately, one way to ensure and enforce these policies is through the protections provided by copyright law.